-
Работа с Atomic Lead Extractor

-
Общие настройки
-
Извлечение адресов
-
Поиск данных
-
Сохранение результатов
-
Фильтрация результатов
-
Полезные советы
-
Регистрация
-
Техническая поддержка
Поиск данных на однотипных страницах
Atomic Lead Extractor способен находить однотипные страницы на сайте и извлекать из них данные. Взяв за основу структуру одной типичной страницы, функция "Поиск данных" дает возможность найти подобные веб-страницы на сайте и извлечь из них нужную информацию.
Для начала работы с данной функцией пользователю необходимо определиться с сайтом, в рамках которого будет проводиться поиск однотипных страниц, и со страницей, которая выступит в качестве типичной при поиске. Функция запускается соответствующей кнопкой в меню программы "Поиск данных".
В открывшемся окне введите URL типичной страницы и нажмите "Enter" для ее загрузки в программу.
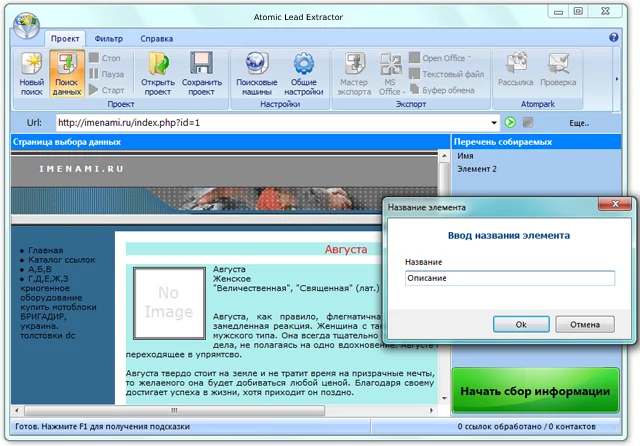
Основным действием является выбор и определение элементов на веб-странице, параметры которых будут учитываться как "типичные" во время анализа страниц сайта и поиска идентичных или похожих. Наведите мышкой на элемент страницы, который нужно сохранить. Выбранная область подсветиться синим цветом. Кликните по элементу и введите для него уникальное название. Выберите необходимое количество элементов, повторяя операцию. Именно совпадение структуры выбранных элементов на различных страницах сайта будет считаться признаком "типичности" и "похожести" веб-страниц.
Настройки поиска данных
Для настройки поиска данных нажмите кнопку "Еще..." (справа от адресной строки) и в открывшейся вкладке установите необходимые значения настроек для повышения эффективности работы программы.
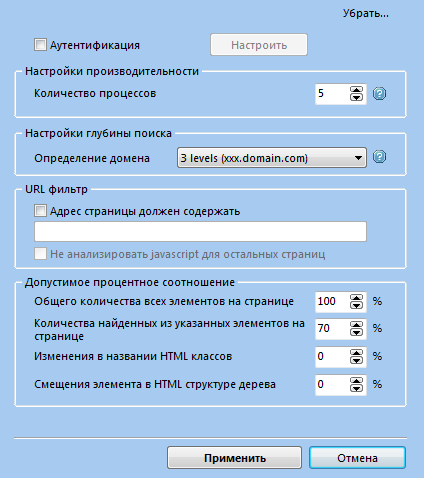
Аутентификация — в случае, если сайт требует авторизации, активируйте пункт "Аутентификация" в настройках функции "Поиск данных", загрузите страницу, введите логин и пароль для доступа на сайт и нажмите "Сохранить". Программа "запомнит" данные авторизации и при повторной загрузке сайта авторизация будет выполняться автоматически, не препятствовать поиску однотипных страниц.
Количество процессов — значение по умолчанию равно 5. Если у вас современный компьютер и быстрое Интернет-соединение, то вы можете увеличить число процессов, в противном случае скорость работы программы может упасть.
Определение домена — поиск однотипных страниц производится программой в рамках одного доменного имени. Пользователь может настраивать глубину поиска до 5-ти уровней включительно.
URL фильтр — применяется для ускорения процесса поиска и включает в себя следующие критерии фильтрации:
- • адрес страницы должен содержать — укажите слова или символы, которые должен содержать URL веб-страницы. Поиск данных будет производиться только на страницах, попадающих под условия фильтра.
- • не анализировать javascript для остальных страниц — если пункт активен и установлено фильтрацию для адреса страниц, программа не будет анализировать javascript на всех других страницах, не соответствующих значению фильтра. Это опция способна значительно ускорить процесс поиска.
Допустимое процентное соотношение устанавливается для определения, какие страницы будут считаться типичными: с полным или частичным совпадением структуры элементов. Учитывается процентное соотношение:
- • общего количества всех элементов на странице — значением по умолчанию принято 100%
- • количество найденных из указанных элементов на странице — значением по умолчанию принято 70%. Это подразумевает, что на страница может быть классифицирована, как типичная, даже при неполном совпадении структуры выбранных элементов.
- • изменения в названии html классов — значением по умолчанию принято 0%, что означает недопустимость каких-либо изменений в html классах выбранных элементов. Например, если элемент, который вы назвали, как "заголовок", в html формате имеет класс , то при поиске типичных страниц программа будет выделять элемент "заголовок" только с указанным классом. В случае, если значение процентного соотношения увеличить, то можно принимать страницу, элемент "заголовок" которой имеет класс , за типичную.
- • смещения элемента в html структуре дерева — значением по умолчанию принято 0%, что не допускает никаких смещений относительно структуры элементов страницы-образца. Если вы хотите извлекать также URL страниц, которые имеют незначительные смещения - следует увеличить значение процентного соотношения.
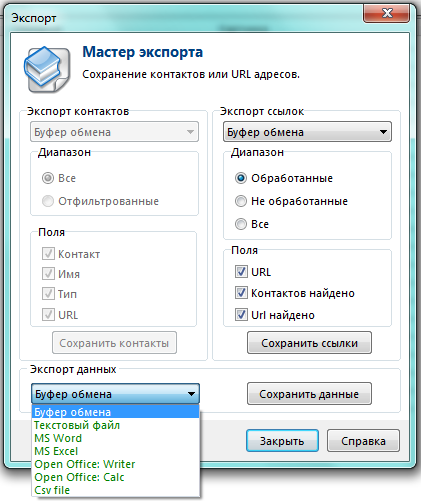
Все найденные данные могут быть экспортированы с помощью Мастера Экспорта в в буфер обмена, текстовый файл, MS Office, Open Office, CSV файл.
Дополнительные разделы:
Начало работы с Atomic Lead Extractor