-
Using the program

-
Common Settings
-
Extract contacts
-
Save extracted contacts
-
Filter menu
-
How to...
-
Registration
-
Custumer Support
Atomic Lead Extractor Data mining
Atomic Lead Extractor can find similar pages within one website and extract data from them. Just define the typical page and run Data mining to find web-pages of the same type and structure, and extract out the information.
First of all you need to select the site within which you will search for similar pages; and also specify the webpage that will be taken as a typical during the search. Start the option by clicking the Data mining button.
Enter typical webpage URL address in the dialog box and click Enter to load the page into the program.
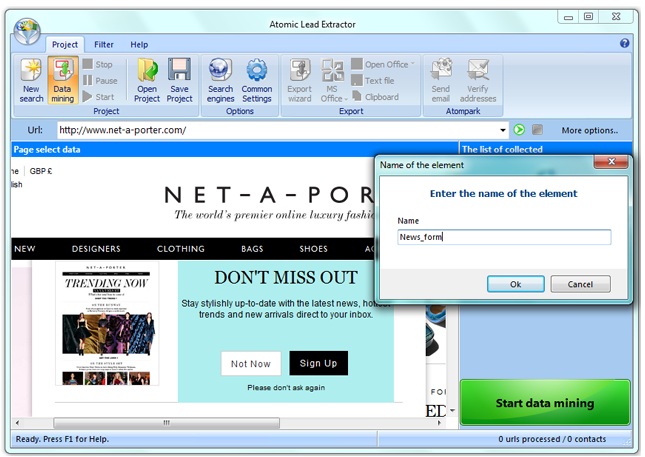
Your main action is to select and determine elements on a webpage, which parameters will be taken as typical ones while web-site analysis and finding identical pages. Point to a webpage element you want to save. This element will be highlighted with a blue color. Click the element and enter its name. Select that number of items that you need, repeating these actions. Complete matching of the selected items structure on different webpages will be considered as typical and similar characteristic of webpages..
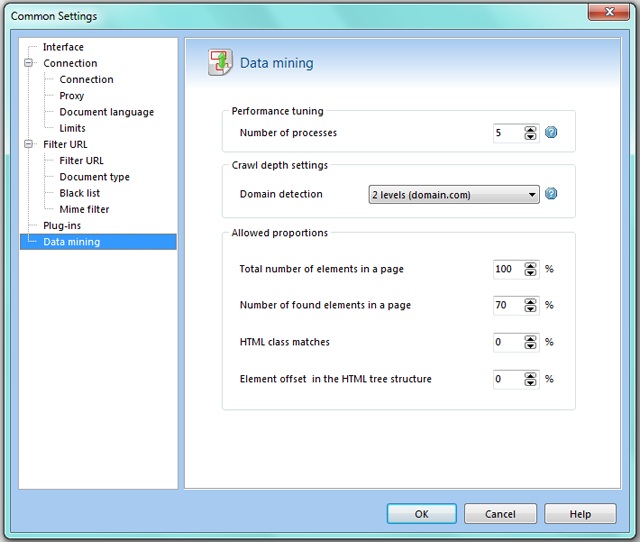
Number of processes means the parameter that depends on the computer power. The default value is 5. You can set more number of processes but should keep in mind that it can influence the program's work-speed, and specifically the search speed.
Domain detection. Atomic Lead Extractor searches for similar webpages within one domain only. You can customize the number of domain levels up to 5 levels to search through.
Allowed proportions are set to determine typical pages: whether with full or partial matching of elements' structure. The following criteria are taken into account:
- • Total number of elements in a page — 100% is a default value.
- • Number of found elements in a page — the default value is 70%. This means that the webpage can be classified as a typical even with a partial matching of selected items structure.
- • HTML class name difference — the default value is 0%. This means the inadmissibility of any changes in the html class of selected elements. For example, you choose an element that has got <class="top_title"> html class and named it "Header". Thus when searching similar pages the program will be detect the "Header" elements with included html class <class="top_title"> only. If you change the percentage value for a bigger, the program will identify a webpage where the "Header" element has <class="top_title_red"> html class as a typical one.
- • Element offset in the HTML tree structure — the default value is 0%. This means the inadmissibility of any displacement within elements' structure of a typical page. If you need to extract URL with little offset, then you should increase percentage value.
Data mining settings
In order to specify Data mining settings click additional button More option (next to the Hunt field) and define the settings value you need to improve search process.
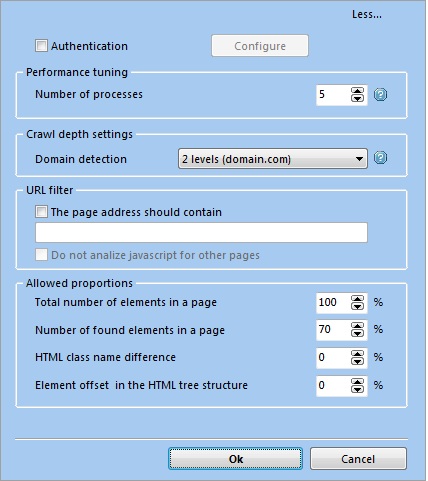
Authentication must be configured if a website requires user authentication. Mark Authentication checkbox, load a page, enter login and password and click Save. Atomic Lead Extractor will "remember" your authentication data and will log in automatically on website reloading for not to get in the way of finding typical pages.
Number of processes means the parameter that depends on the computer power. The default value is 5. You can set more number of processes but should keep in mind that it can influence the program's work-speed, and specifically the search speed.
Domain detection. Atomic Lead Extractor searches for similar webpages within one domain only. You can customize the number of domain levels up to 5 levels to search through.
URL filter is used to speed up the search, and includes the following filter criteria:
- • The page address should contain — enter a word or a symbol that must be in the URL. The search is done only on the pages that fall under the filter criteria.
- • Do not analyze javascript for other pages — if this option is active and you have specified the URL filter, then the program will not analyze javascript on other webpages that do not match the filter criteria. Using this option you can speed up the search.
Allowed proportions are set to determine typical pages: whether with full or partial matching of elements' structure. The following criteria are taken into account:
- • Total number of elements in a page — 100% is a default value.
- • Number of found elements in a page — the default value is 70%. This means that the webpage can be classified as a typical even with a partial matching of selected items structure.
- • HTML class name difference — the default value is 0%. This means the inadmissibility of any changes in the html class of selected elements. For example, you choose an element that has got <class="top_title"> html class and named it "Header". Thus when searching similar pages the program will be detect the "Header" elements with included html class <class="top_title"> only. If you change the percentage value for a bigger, the program will identify a webpage where the "Header" element has <class="top_title_red"> html class as a typical one.
- • Element offset in the HTML tree structure — the default value is 0%. This means the inadmissibility of any displacement within elements' structure of a typical page. If you need to extract URL with little offset, then you should increase percentage value.
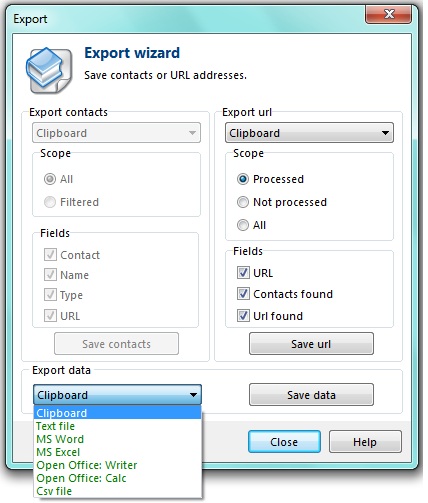
All the data you find and extract can be exported into the clipboard, .TXT file, MS Office, Open Office, and .CSV file using Export Wizard.